
Some AI researchers’ practices are as tired as a Michael Bay movie, to hear Christopher Re tell it.
Wednesday, Re, who is a Stanford University associate professor of computer science, gave a talk for the University’s Human-Centered Artificial Intelligence institute.
His topic: “Weird new things are happening in software.”
That weird new thing, in Re’s view, is that the stuff that was important only a few years ago is now rather trivial, while new challenges are cropping up.
The obsession with models, meaning, the particular neural network architectures that define the form of a machine learning program, has run its course, said Re.
Re recalled how in 2017, “models ruled the world,” with the prime example being Google’s Transformer, “a much more important Transformer than the Michael Bay movie that year,” quipped Re.
But after several years of building on Transformer — including Google’s BERT and OpenAI’s GPT — “models have become commodities,” declared Re. “One can pip install all models,” just grab stuff off the shelf.
What Re termed “new model-itis,” the obsession by researchers to tweak every last nuance of architectures, is just one of many “non-jobs for engineers” that Re disparaged as something of a waste of time. Tweaking the hyper-parameters of models is another time waster, he said.
Instead, Re told the audience, for most people working in machine learning, “innovating in models is kind-of not where they’re spending their time, even in very large companies,” he said.
“They’re spending their time on something which is important for them, but is also, I think, really interesting for AI, and interesting for the reasoning aspects of AI.”
Where people are really spending time in a valuable way, Re contended, is on the so-called long tail of distributions, the fine details that confound even the large, powerful models.
“You’ve seen these mega-models that are so awesome, and do so many impressive things,” he said of Transformer. “If you boil the Web and see something a hundred times, you should be able to recognize something.”
“But where these models still fall down, and also where I think the most interesting work is going on, is in what I call the tail, the fine-grained work.”
The battleground, as Re put it, “are the subtle interactions, subtle disambiguations of terms,” what Re proposed could be called “fine-grained reasoning and quality.”
That change in emphasis is a change in software broadly speaking, said Re, and he cited Tesla AI scientist Andrej Karpathy, who has claimed AI is “Software 2.0.” In fact, Re’s talk was titled “machine learning is changing software.”
Re speaks with real-world authority over and above his academic legacy. He is a four-time startup entrepreneur, having sold two companies to Apple, Lattice, and Inductiv, and having co-founded one of the many fascinating AI computer companies, SambaNova Systems. He is also a MacArthur Foundation Fellowship recipient. (More on Re’s faculty home page.)
To handle the subtleties of which he spoke, Software 2.0, Re suggested, is laying out a path to turn AI into an engineering discipline, as he put it, one where there is a new systems approach, different from how software systems were built before, and an attention to new “failure modes” of AI, different from how software traditionally fails.
Also: ‘It’s not just AI, this is a change in the entire computing industry,’ says SambaNova CEO
It is a discipline, ultimately, he said, where engineers spend their time on more valuable things than tweaking hyper-parameters.
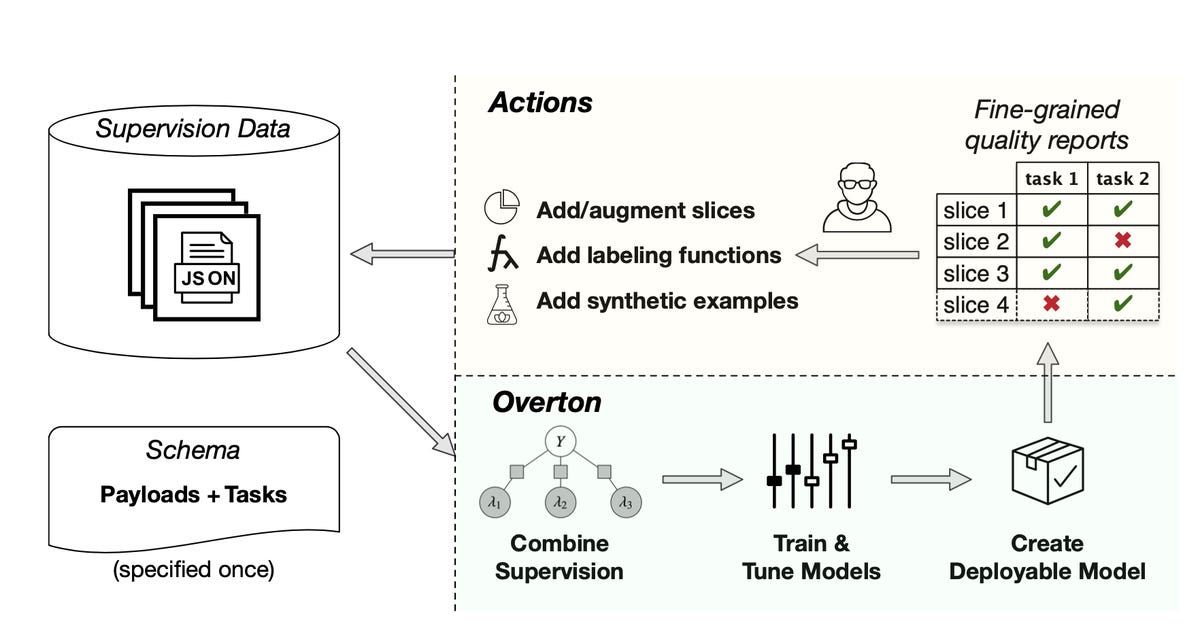
Re’s practical example was a system he built while he was at Apple, called Overton. Overton allows one to specify forms of data records and the tasks to be performed on them, such as search, at a high level, in a declarative fashion.
Overton, as Re described it, is kind-of an end-to-end workflow for deep learning. It preps data, it picks a model of neural net, tweaks its parameters, and deploys the program. Engineers spend their time “monitoring the quality and improving supervision,” said Re, the emphasis being on “human understanding” rather than data structures.
Overton, and another system, Ludwig, developed by Uber machine learning scientist Piero Molino, are examples of what can be called zero-code deep learning.
“The key is what’s not required here,” Re said. “There’s no mention of a model, there’s no mention of parameters, there’s no mention of traditional code.”
The Software 2.0 approach to AI has been used in real settings, noted Re. Overton has helped Apple’s Siri assistant; the Snorkel DryBell software built by Re and collaborator Stephen Bach contributes to Google’s advertising technology.
And in fact, the Snorkel framework itself has been turned into a very successful startup run by lead Snorkel developer Alexander Ratner, who was Re’s graduate student at Stanford. “Lots of companies are using them,” said Re of Snorkel. “They’re off and running.”
As a result of the spread of Software 2.0, “Some machine learning teams actually have no engineers writing in those lower-level frameworks like TensorFlow and Pytorch,” observed Re.
“That transition from being lab ideas and weirdness to actually something you can use has been staggering to me in really just the last three or four years.”
Re mentioned other research projects at the forefront of understanding the tail problem. One is Bootleg, developed by Re and Simran Arora and others at Stanford, which makes advances in what is called named entity disambiguation. For questions such as “How tall is Lincoln,” knowing that “Lincoln” means the 16th U.S. president, versus the car brand, is one of the those long tail problems.
Another research example of more high-level understanding was a system Re introduced last year with Stanford researchers Nimit Sohoni and colleagues called George. AI-based classifiers often miss what are called subclasses, phenomena that are important for classification but are not labeled in training data.
The George system uses a technique called dimensionality reduction to tease out hidden subclasses, and then train a new neural network with that knowledge of the subclasses. The work, said Re, has great applicability in practical applications such as medical diagnosis, where the classification of disease can be mislead by missing the subclasses.
Work such as George is only an early example of what can be built, said Re. There is “lots more to do!”
The practice of Software 2.0 offers to put more human participation back in the loop, so to speak, for AI.
“It’s about humans at the center, it’s about those unnecessary barriers, where people have domain expertise but have difficulty teaching the machine about it,” Re said.
“We want to remove all the barriers, to make it as easy as possible to focus on their unique creativity, and automate everything that can be automated.”